Whiz: Data-Driven Analytics Execution
This paper by UTNS lab appeared in NSDI 2021. It presents a data-analytics framework that decouples intermediate data from computations.
Whiz addresses several challenged posed by current analytics frameworks. The first one is data opacity. Most modern data analytics frameworks relies on MapReduce execution engine. The developer specifies the map and reduce function, which then get submitted to the analytics framework. The workflow can be expressed as a logical graph; the physical graph (which includes the cluster configuration, disk quota, etc.) is generated transparently. The workflow is shown below:
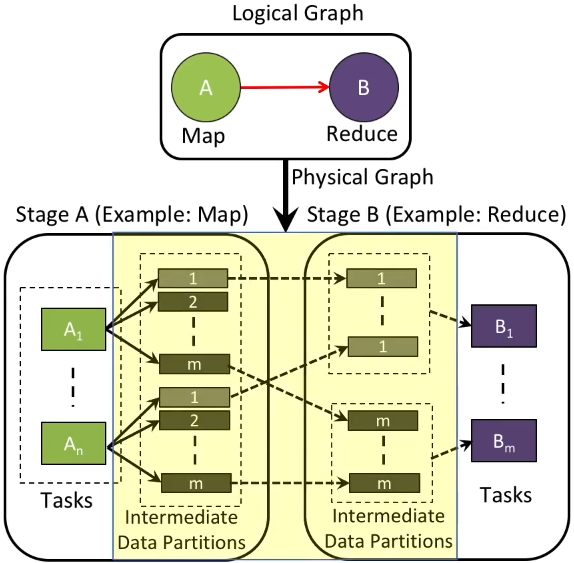
The problem is in the region marked yellow. It shows the execution engine has limited runtime visibility into the intermediate data. Thus, adapting processing logic of tasks based on the states of intermediate data becomes challenging.
In addition, task parallelism and intermediate data partition strategy are often static. In the graph above, the intermediate data partition tasks and the final reduce tasks might be determined prematurely, without taking the intermediate data partition characteristics into account. For example, data skew (unevenly distributed jobs) causes different reduce nodes to process different amount of tasks. The graph below illustrates how the shuffle stage can result in disproportional intermediate data partitions.
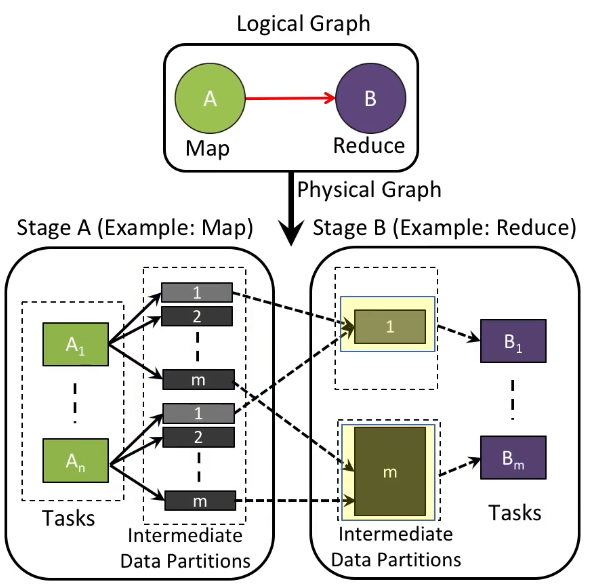
Finally, Whiz addresses the limitation posed by compute-driven scheduling. In compute-driven scheduling, one stage usually relies on the completion of the upstream tasks, the may lead to compute idling waiting for remaining data to become available, even if the a subset of workers in the current stage is ready for execution. Decoupling data from computation enables the execution engine to treat intermediate data as first-class citizen, thus allowing finer-grained control of data processing.
In summary, Whiz solves two problems presented in compute-centric execution engines:
- Tight coupling between intermediate data and compute.
- intermediate data agnosticity.
Thus, Whiz creates a feedback loop between the execution service and the data service so that the execution can dynamically adjust its policy based on the information offered by the data service to optimize system performances.
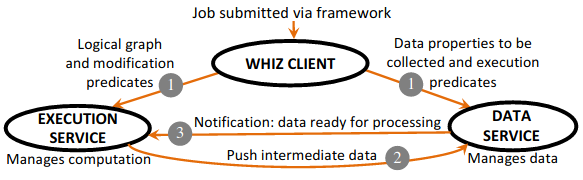
Whiz classifies itself as a data-driven execution engine, which drives execution based on intermediate data properties. Making intermediate data visible opens door for optimization opportunities, thus increasing performances. For more technical details regarding the architecture and implementation of Whiz, please refer to the original paper.