Virtual Memory Overview
I love pointers. Pointer is very a useful feature in programming languages like C/C++. I can pass weird hexadecimal numbers to a function and then it will magically locate where the program is in memory. However, all those values we see are merely virtual addresses, a running program’s view of memory in system. Any address we can see while programming user-level programs is a virtual address. It is no more than an illusion of where the data is actually laid out in memory. Only the almighty OS knows where the data actually locates in physical memory.
Three Goals of VM
When the OS provides this layer of abstraction to translate virtual address to physical address, we say that the OS is virtualizing memory. In order to achieve virtualization, there’re three goals to keep in mind.
Transparency: The OS will implement transparency in a way that is invisible to the running program. Usually, transparency would suggest a clear understanding of how things work. However, when we are talking about VM, it means the running program is unaware of the fact its memory is translated by the OS(and hardware) behind the scene.
Efficiency: The OS should do its best to ensure the efficiency of virtualization, in both time and space. Some of the methods used to improved efficiency, including hardware components like translation look-aside buffer(TLB), will be discussed in the following chapter.
Protection: Being able to protect processes from interfering each other or even the OS is important. When one process performs actions like read and write, the process should be isolated so that it’s unable to modify the data of other processes or behave maliciously.
Basic Concept: Address Space
Before we start, there are several terms I will use throughout the discussion so it’s better to get familiar with them.
Physical address space: it is merely a collection of physical addresses used by the hardware. The value of the address can range from 0 to the MAXsys. The address is actually utilized by the physical memory to fetch the contents inside.
Logical/Virtual address: It a collection of address a process is able to access (the process is not aware of the actual physical location). It can be bigger than physical address due a technique called paging which will be discussed later.
Segment: A chunk of memory assigned to the process to use.
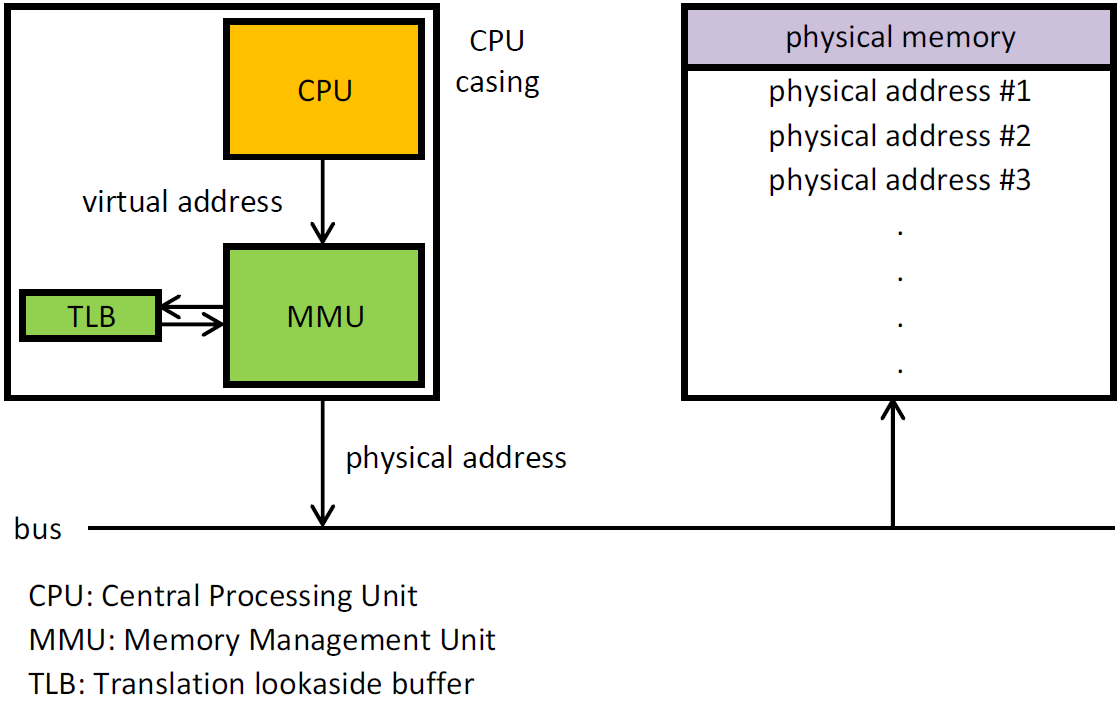
How does an address get generated
Uniprogramming: This is a very simple scenario, there’s only one process executing at the moment, its address always starts at 0 and the OS is loaded in a fixed part of the memory. The process executes in contiguous section of memory. The process is able to use the all the available portions of the memory as long as it doesn’t touch the OS’s property.
Relocation
Same as uniprogramming, the OS locates at the highest location in the memory. The OS allocates a contiguous segment of memory for processes to use. If it doesn’t have enough space, it simply wait the process to terminate. The relocation address (also known as base address) is the first physical address a process can use. Limit address is the largest physical address the process can use.
Also note there’re two types of relocation:
static: The address is produced during load time and the process is load into the given location to execute. The OS can’t move it as soon as the process is loaded in. Note the static address can be changed in both linking and loading stage. Linking stage might involving library routines and loading stage might increment the base address by the amount of memory used by previous process already present in memory. Note the printed value here is the actual physical address, not a virtual address.
dynamic: Physical address is obtained by adding the base register to virtual address. The result has to be less than bound register or an exception will be raised by the processor.
Problem with relocation:
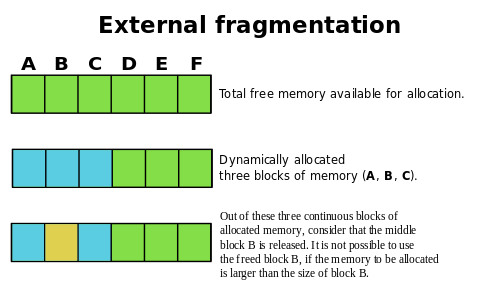
Even though the concept of relocation is easy to understand, it can easily lead to problems with unused memory space. The biggest problem is external fragmentation. When a process finished executing and the memory it occupied is deallocated, it will leave a “hole” behind and become available for other process to use. The problem is, as the size of the emory of the previously running process can be any random number, the “hole” it leaves behind may be too small for other processes to fit in. Even if it is big enough for other processes to fit in, they may eventually lead to smaller fragments that are too small for a process to use, which leads to external fragmentation. There’s also another problem called internal fragmentation, but it won’t be discussed here.
How to minimize external fragmentation?
As we can see, relocation leaves rooms for external fragmentation, which can be a problem since unused spaces will be a waste. Are there any methods we can use to reduce the external fragmentation to minimize external fragmentation and better utilize the free blocks? There’re three policies we will discuss that can be used to achieve our goals. A reminder is that they can’t completely eliminate external fragmentation but merely minimize it to a certain level.
Policies
First-Fit policy
Finding the first free block that can hold the requested amount of memory.
Requirements:
- All free blocks are tracked in a list and sorted by address.
- Allocation requires a search throughout the list to find the first free block to fit in the memory.
- After deallocation, the freed block might need to be merged with other free ones.
Pros:
- very easy to implement.
- Tend to produces large free block towards the end of the address space.
Cons:
- Allocation is slow.
- It will eventually lead to fragmentation.
Best-Fit policy
Finding the smallest free block to allocate the request memory.
Goal:
- Avoid fragmenting huge free block.
- Minimize the size of external fragmentation.
Requirements:
- All free blocks are tracked in a list and sorted by address.
- Allocation still needs a search in the list to find a suitable block to fit in.
- After deallocation, the freed block may need to be merged with other free blocks.
Pros:
- Kinda simple to implement
- Reduce external fragmentation, works well when allocations size gets smaller.
Cons:
- Still leaves room for external fragmentation.
- When it is deallocated and merged back, the new free block may require to be resorted.
Worst-Fit policy
Finding the largest free block to allocate request amount of bytes.
Goal:
- To avoid having too many small free segments(reduce external fragmentation).
Requirement:
- Free blocks sorted by size
- Allocation is fast since the first one is always the largest one.
- After dealloaction, it needs to check if the new free block needs to be merged back and resort the list.
Pros:
- Works great if all allocations are of medium size.
cons:
- Still external fragmentation
- Deallocation is slow(need to resort and merge)
- Tends to break down large free blocks, which can lead to failure to allocate large blocks.
Technique to further reduce and eliminate external fragmentation will be discussed later.
Dynamic Relocation
Advantages
- Processes can move during execution.
- Processes can grow over time.
- It’s easy to provide protection since we only need two registers.
- Fast and simple
Disadvantages
- Allocation is contiguous.
- Sharing memory is hard since there’re no way to set base and bound register to be the same for more than one processes.
- Multiprogramming is limited since all active processes have to be loaded into the memory, which creates another problem that physical memory becomes the limit for how many processes can be loaded. (Swapping might help but the number of active processes still needs to be in the memory.)
- Need to add memory references every allocation.
- Memory management is a mess.
- Everyone has the same permission throughout the address space, which can potential create problems.