Stichable Neural Networks
TLDR; the Stichable Neural Networks paper includes some interesting concepts. It allows the creation of multiple neural networks with varying complexity and performance trade-offs from a family of pretrained models.
Key Principles
- How to choose anchors from well-performed pretrained models in a model family
- The design of stitching layers
- The stitching direction and strategy
- Simple but effective training strateg
A key question about combining sub-networks from different pretrained models is how to maintain accuracy. The paper concludes that the final performance of these combinations is nearly predictable due to an interpolation-like performance curve between anchors. This predictability allows for selective pre-training of stitches based on various deployment scenarios.
The Choice of Anchors
Anchors that are pretrained on different tasks can learn very different representations due to the large distribution gap of different domains. Therefore, the selected anchors should be consistent in terms of the pretrained domain.
The Stitching Layer and its Initialization
SN-Net is built upon pretrained models. Therefore, the anchors have already learned good representations, which allows to directly obtain an accurate transformation matrix by solving the least squares problem:
$$||AM_o - B|| = min||AM - b||_F$$
where $A \in R^{N \times D_1}$ and \(B \in R^{N \times D_2}\) are two feature maps of the same spatial size but with different number of hidden dimensions.
This function indicates a closed form expression based on singular value decomposition, in which case the optimal solution can be achieved through an orthogonal projection in the space of matrices:
$$M_o = A^\dagger B$$
where $A^\dagger$ denotes the Moore-Penrose pseudoinverse of $A$.
Where to Stitch
SN-Net takes Fast-to-Slow as the default stitching direction, meaning it will stitch bigger and slower network after smaller and faster networks to achieve better model performance. Besides, it also proposes a nearest stitching strategy by limiting the stitching between two anchors of the nearest model complexity/performance.
Way to Stitch
Prior works shows neighboring layers dealing with the same scale feature maps share similar representations. Therefore, SN-Net uses slideing window: where the same window shares a common stitching layer.
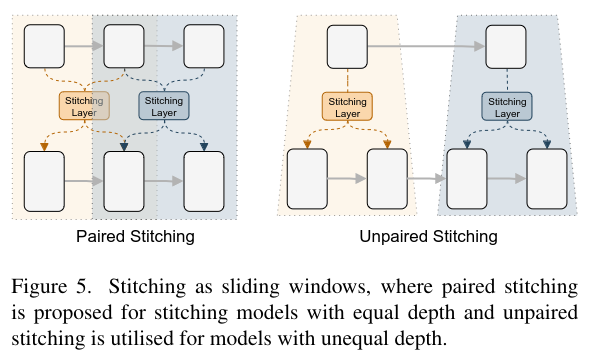
Stitching Space
The stitching space is controlled by the configuring the sliding window kernel size $k$ and step size $s$.
Training Strategy
The training algorithm of SN-Net can be described as:

The training algorithm can be summarized as:
- Firstly define a configuration set that contains all possible stitches
- Initialize all stitching layers with least-squares matching
- At each training iteration, we randomly sample a stitch and follow the standard training process as in common practices