Specifying Token Ring for Mutual Exclusion
Mutual exclusion is a common term appearing frequently in computer sciences. In essence, it’s a mechanism of concurrency control allowing exclusive access to some resource (or “critical region”). Token passing is an algorithm for distributed mutual exclusion (DME) and will be our focus in this post.
DME specifications usually make the following assumptions:
- Network delivers message in order, e.g. TCP (sometimes)
- Every message is eventually delivered (usually)
- Messages are never duplicated. Duplication may result granting resources to multiple clients, which is not what mutual exclusion demands (usually)
Thing we might want to guarantee for DME specifications are:
- Mutual exclusion, at most one client is in a critical section (always)
- Non-starvation. A requesting client enters critical section eventually (usually)
- Non-overtaking. A client cannot enter critical section more than once while another client waits (usually)
In addition, we need to analyze DME algorithms’ performance metrics, which usually includes:
- Message complexity, e.g. number of messages sent between clients being served
- response time, or time between request and entering CS
- Throughput, or rate of processing CS requests
Let’s take a token ring as an example. In a token ring, a client holds a token and then sends it to the next one after exiting its critical section. When we make assumptions about a token ring, we
- do not need to have network delivering messages in order, because at any given time in a token, there is at most one message in transit.
- ensure every message is eventually delivered. Otherwise, the system won’t make progress, and we will not have non-starvation guarantee.
- need non-duplication for messages. Otherwise, we violate the fundamental properties of this protocol, or no mutual exclusion.
- clients don’t spuriously release. This will be clear later when we demonstrate what happens if clients release multiple times.
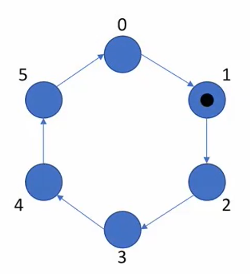
We want to guarantee that
- mutual exclusion holds.
- non-starvation
- non-overtaking, because token will get through every client in the network first because repetition happens.
To analyze token performance, we use the above performance metrics (message complexity, response time, and throughput)
- Message complexity: when the system is under low load, the message complexity is unbounded because there may be an arbitrary number of messages being sent throughout the network where no one is in the critical section. When system is under high load, the message complexity is 1.
- Response time: when the system is under low load, there could be \(N\) messages times (where \(N\) is the total number of clients). When under high load, the response time would be 1 message time.
- Throughput: the maximum throughput would be 1/(message time + CS time)
A naive specification for mutex in Ivy would be:
action grant(v:id)
action release(v:id)
specification {
var lock(X:id):bool
after init {
lock(X) := false;
}
before grant {
require ~lock(X);
lock(v) := true
}
before release {
require lock(v);
lock(v) := false
}
}
To see token ring in action, we use the demo from Ken’s presentation:
#lang ivy1.8
include network
include numbers
global {
type host_id = {0..max}
alias token = uint[1]
instance net : tcp.net(token)
}
process host(self:host_id) = {
import action grant
export action release
specification {
var lock : bool
after init {
lock := false;
}
before grant {
require forall X. ~host(X).lock;
lock := true;
}
before release {
require lock;
lock := false;
}
}
implementation {
instance sock : net.socket
after init {
if self = 0 {
pass
}
}
action pass = {
var tok : token;
var next := 0 if self = max else self + 1;
sock.send(host(next).sock.id, tok);
}
implement sock.recv(src:tcp.endpoint, val:token) {
grant;
}
implement release {
pass;
}
}
}
We put the above code into a file called token_ring.ivy and compile it using ivyc token_ring.ivy. Then we launch the program using ivy_launch max=2 token_ring.ivy, which opens three terminal windows.
If we type in host(1) with host.release, we see in host(2) it outputs host.grant, which seems to show that the token work properly. However, if we type host.release again in host(1), host.grant will show up again in host(2), resulting in multiple tokens getting created, which violates the requirement that there is at most one token in the ring at any given time.
If we execute ivyc target=test token_ring.ivy && ivy_launch max=2 token_ring.ivy, then we see the token ring work properly. The reason is we have specified the requirement for grant and release (require forall X. ~host(X).lock for grant and require lock for release).
grant is an action imported from the environment, thus we know when grant happens, all clients in the network do not hold a lock. On the other hand, release is an action exported from the system, which means the tester must perform grant given the host has the lock. So the tester won’t perform release multiple times like we did above because the tester can not violate the require lock requirement.