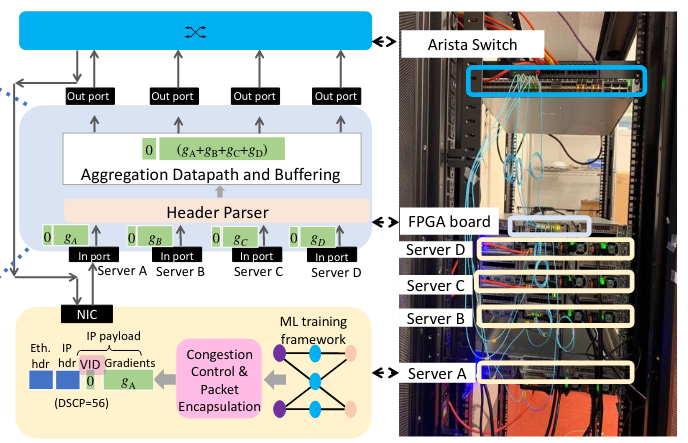
In-Network Aggregation for Shared Machine Learning Clusters
This paper by Nadeen appeared in MLSys 2021. It presents an in-network aggregation framework called PANAMA for distributed ML training tasks. PANAMA has two components: (1) an in-network hardware accelerator with support for floating-point gradient aggregation; (2) a domain-specific load-balancing and congestion control protocol.
Motivation
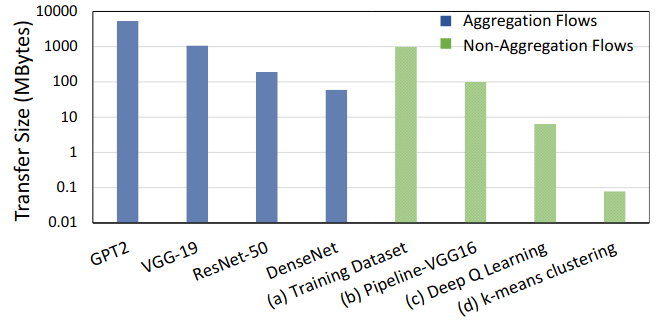
The primary motivation behind PANAMA is the data-parallel training (in which the neural network is replicated across \(N\) worker where each worker processes a subset of the training data) demands constant local gradient exchanging at every iteration, thus creating a huge amount of traffic.
For example, for a training job with \(1000\) workers and 1 GB DNN model size requring \(1000\) iterations, the total traffic will be about 2 PB.
Network Design
The paper assumes a traditional data center multi-tier folded Clos topology:
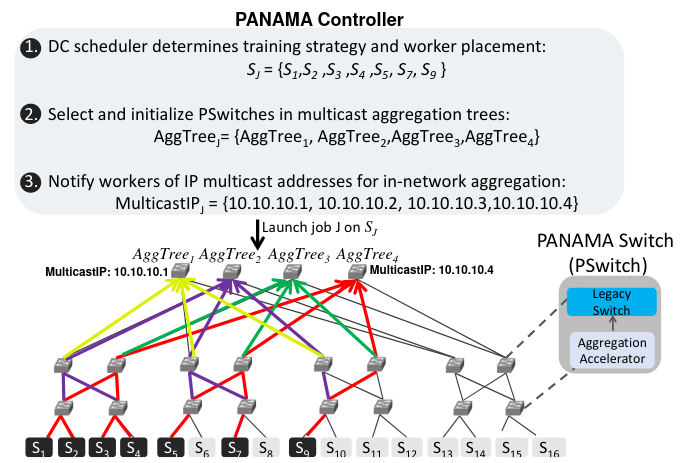
PANAMA uses multiple aggregation trees per training job to spread the traffic across multiple paths and avoid congestion hotspots. This is different to equal-cost multi-path (ECMP) protocol because the aggregation flows are typically large. Bounding such flows to a single aggregation tree will create network imbalance.
Congestion Control
PANAMA uses implicit acknowledgments instead of traditional point-to-point approaches. Because each aggregated packets are constructed on the fly, one-to-one mapping between packets and the acknowledgements is unnecessary, if a worker receives aggregation results, that automatically serves as an implicit acknowledgement. This eliminated the need to keep a per-flow congestion state at PSwitches.
Similar to DCTCP, PANAMA relies on ECN marks in the IP header to react to the network congestion. Since aggregation packets are created on the switch, each hardware accelerator need to perform a bitwise \(OR\) on the ECN field of received packets to mirror the traditional ECN bit.
Hardware Design
The design of the aggregation accelerator in PANAMA is straightforward: it utilized the SIMD architecture in which the gradients are partitioned across adder trees. Adder tree can operate in parallel and pack the results and sent them to the output ports. The VID fields are merely used to correct aggregation.
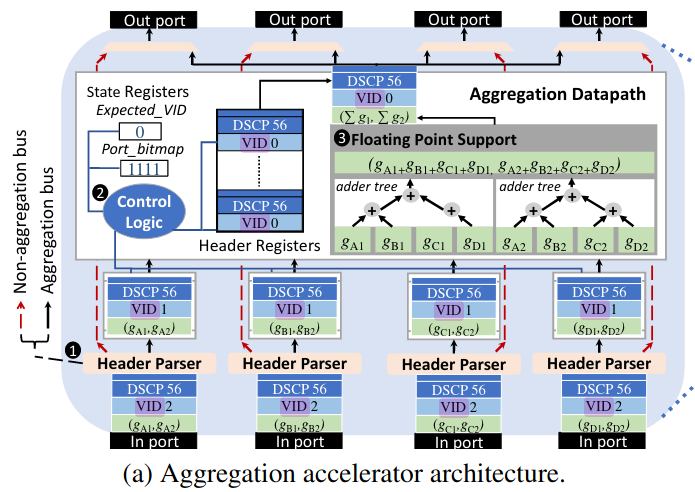
Overall, the workflow is really simple and illustrated below: